Code Review #2
We held our second code review this Friday. Two months between holding code reviews is a little long, but we’re still working out the process. Some things to remember for next time:
- Prepare for the code review ahead of time. This code review was being held towards the end of the Sprint, so the afternoon before we got it arranged. Some review is better than none, but the code review ended up being more of a code walk-through.
- Adding a static analyzer like Checkstyle really helps with keeping the code clean. Since the developers had spent a good bit of time working down 150+ Checkstyle warnings to 9 there were very few basic defects, like one character variable names, or really long methods.
- Figure out a better way to do followup. After 90 minutes we had a number of items to fix, but since they were handwritten notes by all the participants it will be a bit difficult to check up on. We may get a chance to use a tool like Crucible the next time around.
- Next time don’t even hold the review until all the classes covered have tests. Two of the reviewed classes had zero test coverage.
On the positive side we found quite a few subtle defects in 90 minutes from cut and paste errors to iterating over collections that only had one item. I think the three of us were all in agreement that having new pairs of eyes on the code was really helpful in catching some things.
JSF At First Glance
Richard Monson-Haefel blogs about looking into JSF. Some of his comments include:
“It really seems complicated to me in terms of configuration, debugging, and such things.”
“JSF strikes me as an over-engineered solution that meets the needs of a small percentage of enterprise web sites.”
Appears to be seeing JSF for what it is right now. Interesting technology that isn’t that cleanly implemented. I really wonder how well JSF will succeed out in the world unless they can fix some of the difficulties with logging, debugging, and unit testing. That said we’re still pushing hard to make it work on several projects. One developer even mused recently that using a component with some built-in paging functionality, finally made him feel like there was something positive in JSF.
Test Driven Adoption Poll
Methods and Tools online magazine ran an actual poll on TDD within software organizations. The poll had 460 total votes. The poll asked the question how is unit testing performed at your location?
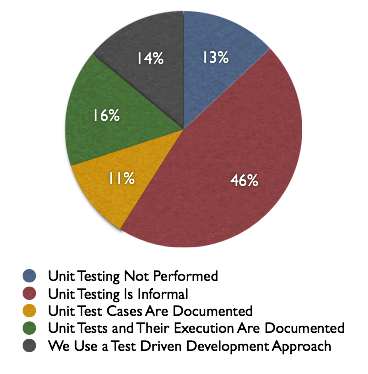
So TDD adoption is still slow going, which has been my anecdotal experience as well. The nice thing is if you can get there you gain a large competitive advantage over the 59% of shops that don’t really do any unit testing. My guess is informal unit testing means hardly any unit tests, or one developer is trying to do them and everyone else is ignoring them entirely.
I’m not really sure what the documented unit test cases are. Does this just mean that the unit tests are described in some documentation? And does the documentation of execution mean the tests are run through cruisecontrol or a similar tool? No way to know the answers to these questions.
My group is writing unit tests, typically after the fact, so not true TDD. Still that’s our end goal and a few developers are doing some TDD. We also have cruisecontrol executing all our tests with every code checkin.
The promising suggestion of this poll (unscientific of course) is that TDD is making headway with developers despite the initial alien feeling of writing tests first.
Sprint Day #29 and Burndown Charts
On many of our Sprints on various Scrum projects a curious burst of productivity takes place. Without warning many tasks like the following are suddenly completed:
- Document the migration process.
- Fix defects.
- Research indexed search options.
Generally most of these tasks were either not even started or had been in progress for most of the Sprint.
So on day #29 at the daily Scrum the ScrumMaster stands up and starts asking the obvious questions. So are we really going to do task X at all, and does it really impact the Sprint goal? Pretty quickly piles of stalled tasks are removed because the team thought they were important at some point, but they’re no longer relevant, or just don’t add any real value to the current Sprint. So when you print out the last burndown chart for the Sprint a steep cliff shows up at the end assuming you’re actually going to make your Sprint goal.
I’ve seen this happen on several different Scrum teams now. It does make the progress of the team a little less transparent since if you look at the remaining work or the burndown chart it often appears that the team is in danger of not making its goals in the middle of the Sprint even though they feel they’re progressing fine. Especially if you’re looking in from the outside you may wrongly assume that the Sprint is in big trouble and corrective action needs to be taken immediately to negotiate out some of the scope for the Sprint.
When I’ve played the ScrumMaster role I’ve played it by ear since with daily Scrums and gentle corrections along the way I intuitively feel like I know where the project is. I also tend to use a big cork board to track progress which gives me a good visual. In the past on more traditional waterfall projects with Gantt charts I played it by ear as well since I never felt the Gantt chart was a true measure of where the project was.
My thoughts on how to improve this is to question the various tasks more along the way and determine if they shouldn’t be pulled or considered complete earlier in the Sprint to keep the burndown chart more accurate. All it should require is some discipline. I do wonder as well if the team will still want to hold onto tasks that they think are necessary.
Rake 0.7, Rails 1.0, appdoc target
Ran into a minor inconvenience going through Agile Web Development with Rails. Running the command:
rake appdoc
Results in the following error:
rm -r doc/app unrecognized option `--line numbers -- inline-source' For help on options, try 'rdoc --help' rake aborted! exit
Didn’t take to long to find the source of the bug. Just change one line in
|
1
|
/usr/lib/ruby/gems/1.8/rails-1.0.0/lib/tasks/documentation.rake
|
. So:
rdoc.options < < '--line-numbers --inline-source'
Becomes:
rdoc.options < < '--line-numbers' << 'inline-source'