Developers and Desktop Databases
Typically development groups fall into one of two patterns:
- Shared development database – every developer shares a single centralized development database often managed by a DBA group.
- Desktop databases – every developer has an individual instance of the database.
The practice has evolved over time and developers tend to follow precedence on it. Historically, developers didn’t think of running a local database, primarily because of the resources involved. Installing and running something like Oracle locally used to be a significant drag on a development machine. You were already trying to run some sort of IDE that sucked up most of your machines resources so running the database locally wasn’t a great option. If you were lucky enough to be running a pretty light weight database you might think about running a local copy, but otherwise you just setup a connection and shared the dev instance.
As machines have gotten quite capable of running databases, IDEs, and even virtual machines all at the same time the option to run a local copy of the database became very real. In this case a number of developers began to install and run local copies of the database. Running your own local copy quickly makes some development issues stand out:
- You have to learn a bit more about how your target database software is setup. Suddenly it’s just not just a set of connection parameters.
- You have to think about the best way to coordinate changes to the database model. Making a lot of changes locally to apply later to the central dev integration instance is going to end in a lot of angry emails with how you broke the build.
- You can quickly experiment with local changes to the database model without impacting the rest of the team.
- You have a truly complete development environment, so if you take your laptop home at night, work remotely for the day, or get called for troubleshooting in the evening you can be effective without having to VPN into the dev database or drive into the office.
I think the long term trend is most developers will run local instances of their target database. This is almost standard in startups and newer organizations. As a consultant I love having a complete development environment since I can run and demo the project at a moment’s notice. The issues with integration are being addressed with approaches like database migrations in Rails and maintenance of DDL in source control, treating it like an equal member of the code. I’ve also seen partial steps towards this model with the idea of in-memory local databases used for unit/integration testing where you use an ORM like Hibernate to build the database model on the fly whenever you need to run tests.
Spock Intro Tutorial

I gave a presentation on Spock a very nice BDD framework in Groovy a few months back to our Groovy Users Group in Sacramento. After using it on a real world Grails project the last few months it has grown on me to become my go to testing framework for Groovy/Grails or Java projects. A typical specification looks something like this:
def "a pager should calculate total pages, current page, and offset"() {
when: "count, rows and page number"
def pager = new Pager(count, rows, page)
then: "should return correct total pages, the current page, and the offset"
pager.totalPages == totalPages
pager.currentPage == currentPage
pager.offset == offset
where: "you have a number of different scenarios"
count | rows | page | totalPages | currentPage | offset
100 | 10 | 1 | 10 | 1 |
950 | 100 | 5 | 10 | 5 | 400
72 | 20 | 3 | 4 | 3 | 40
}If that passed your 5 second test take a look at a fuller introductory tutorial I put together.
A Gentle Introduction to Spock
And if you want to try out executing real code the project has a nice browser based environment at Meet Spock.
AgileZen for Solo Remote Development
Over the past few months I’ve been working on some remote projects as a solo developer. Knowing I wanted a light weight tracking tool I took some time to experiment with a few tools and I’ve recently come to appreciate the lightweight character of AgileZen.
Despite many warnings to use the simplest thing that could possibly work, often stickies on the wall or simple index cards, there have always been a number of options to translate these planning/tracking tools to software applications. Despite settling on the power of physical wallboards for collocated teams throughout my career I have looked into using a number of tools for feasibility ultimately deciding none of them worked as well as a cork board and some stickies or index cards. Tactile and visual cards rock.
Some of the tools I’ve looked at in the past include:
- XPlanner (an very old tool in the space)
- Basecamp
- Excel
- Rally
- Scrumworks
- Pivotal Tracker
- Trac
- Mantis (a bug tracking tool used for planning)
I never felt any of them where worth the effort to maintain in the end despite many high hopes. I’m not immune to tool fascination, but I tried to honestly evaluate the worthiness of the given tool. As a manager much of my focus on this was to please stakeholders and other managers with a nice visual report that could be shared via email and web browsers. In my Agile rollouts it turned out that I was ultimately more successful showing off my cork boards and cards. We did maintain an Excel spreadsheet with backlogs as well to meet some documentation standards for PM groups. It was a small compromise I was willing to live with.
My most recent projects presented me with a different challenge. As a solo developer I’m largely on my own and not sharing the project tasks with anyone else, but I like to have an organized workflow at all times. My home office doesn’t have much in the way of space for a nice corkboard, and again I wanted to fiddle with tools so I tried a few to see how they might work for me.
A first attempt was with Pivotal Tracker. I love the things Pivotal is doing out there with a focus on TDD/BDD, pair programming and producing high quality code. Pivotal Tracker is a nicely polished tracking tool that largely simulates the idea of a wall board with an emphasis on iterations that contain a set number of story points. It’s an opinionated piece of software with this and assumes that you are very concerned with ordering of stories based on points and how you pull them into the backlog. After a lot of work trying to understand how it wants me to work I found it not a great fit as a solo developer. It assumes you want to have tracker plan your iterations automatically based on your velocity. In fact they admit that you can change some settings for the current iteration to allow you to drag stories in or out, but it will still automatically plan all the other iterations in the backlog. In the end I might be up for trying it with a non-collocated team, but for a solo developer the overhead was a bit higher than I prefer.
AgileZen was my second attempt. I remember from some old twitter and blog posts that several people had said it was a really nice lightweight tool. I realized arriving at the site they had been acquired by Rally. I’ve used Rally’s tools, but for collocated teams I didn’t really think the overhead of using Rally was worth it. It appears that AgileZen is their attempt to provide a lighter more Kanban style tool. I liked the little bonsai tree on the login and found more to like when I went in and attempted to setup my current project. I watched the short series of screen casts showing how it worked, maybe 5-10 minutes in all. After that I’ve been very productive without having to dig into any help. The central metaphor is just a digital task board:
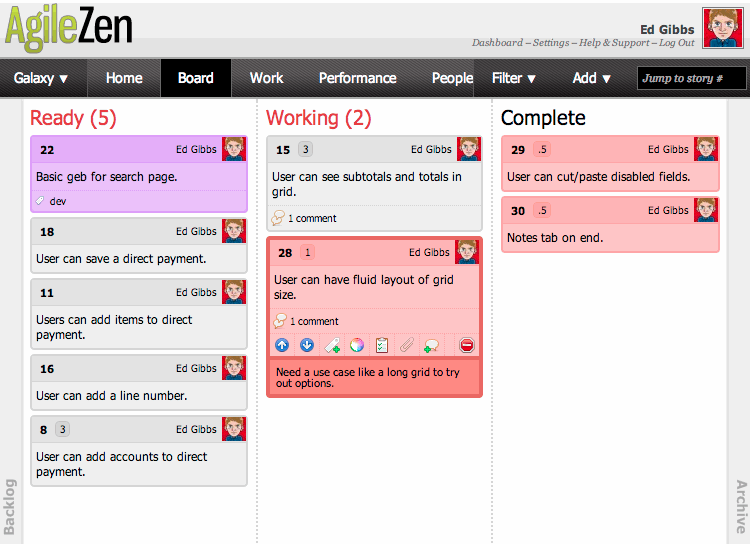
Agile Zen focuses on the concept of cards and a board with very lightweight workflow. You create a feature or user story and ‘hang the card on the wall’. You then just move the card to progress it from the backlog to started. You can do some customization, but the default workflow was perfect for me as a single developer. It also looks like it works quite well for remote teams and appears to support more options like marking cards as ready or blocked. I’ve even used the blocked status for a card once where I wanted to run a design idea by a colleague before I continued further on that particular story. And I’m a sucker for some auto-generated stats, but it has a nice page where it calculates your throughput with a pretty graph. It will take more time to see if the stats actually give me useful feedback, but did I mention they look nice:
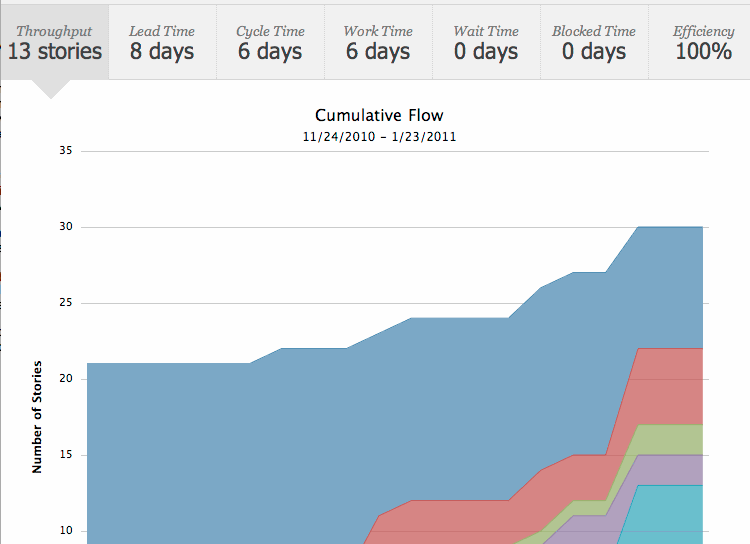
Overall the tool feels closer to a digital taskboard than anything else I’ve experimented with. I’d still use a physical task board for a collocated team, but for a team working in remote locations or a single developer I think it makes a very good electronic substitute. Now if only it had an iPad version. If you’re a solo developer feel free to try it yourself as it’s 1 project is free for a single developer.
Fallback Plan in Action: From Software Manager to Developer
Everyone relishes the confidence of a having a backup plan if everything falls apart. For myself as a manager it was knowing I could always go back to development if something unexpected came up. After 10 years as a development manager, I got the unfortunate call to follow my director to an unannounced meeting first thing in the morning. Turns out the CIO had decided the organization didn’t need developers and could get by with contractors so there was no need for a development manager. My director would depart the company as well a few months later.
I was in a state of shock for a few days. Sacramento is a small IT market normally and finding open development management positions is fairly rare. I explored a number of options for the first month afterwards including biting the bullet and taking a great job in the Bay area but living with a horrible commute and lousy family life. For many reasons I choose family over a nasty commute.
I came back to the plan of returning to a developer/architect/tech lead role. I hadn’t done day to day development in at least 5 years, but I’ve always kept up my skills with home projects and taking on the tasks of running infrastructure tools like source control, CI servers , wikis, and functional testing tools. I really enjoyed managing development teams and moving obstacles and really growing the skills of my team, but now it was time to focus on myself.
Fear was right up front. I felt like an impostor in the first few development interviews all of which went well despite this. I’ve never felt a high degree of confidence in my abilities and always felt the need to prove myself. With my background as in professional services I eventually got acclimated to the feeling that I was an impostor working on the client’s project. It motivated me to spin up incredibly quickly so I wouldn’t be exposed as a fraud. I’m still not sure this has been the healthiest approach, but I’m still working through my affliction with the Impostor’s Syndrome.
Another factor was figuring out how comfortable I was with making less. Development managers simply make more than senior developers. I’m certain this is the wrong approach in many cases as I always felt at least my top few people were more important to the company than myself, but HR departments really like hierarchal salary structures. So diving into development was likely to mean a salary hit. I have a wonderful wife, two kids, and a hefty mortgage. The prospect of taking a startup job with a firm that was a using new technologies was enticing, but taking a big salary cut was going to be very hard. Lesson learned with the mortgage, sometimes the nice new house isn’t worth the career choices it forces you into to, but you end up making some compromises in life.
I ended up deciding I had to hold out for a well paying position even if that meant working for less exciting companies and technologies. It probably meant a lot of Java/J2EE given my background instead of Groovy/Ruby or mobile development.
Anyway after a month or so of doing some big career thinking, visiting family and friends, and polishing up some slightly rusty Java chops I dipped my toes back in the water with a couple one off gigs for a former employer. I took on a mentoring an organization through development tool choices and how to guide their staff on working with these new tools. From there I took an assignment to do a custom WebLogic course for a client. It was a week long course which I felt I could ramp and cover, but brought back a lot of lingering doubts.
I’ve done many presentations over the years ranging from an hour or two to a half day seminar. I feel very confident in the ability to deliver them with a high degree of quality. Before this I had done two week-long courses in the past and survived them both, but walked away from each feeling as though I had done a horrible job. Keeping a class engaged and interested in a topic for an entire week and knowing it deeply enough to answer almost any question is quite a tall order. So the WebLogic course was a big challenge.
I spent a week immersed in the course material and working through the labs several times after building a VMWare image. I prepped in front of the director of the company, feeling like I was going to fail. I delivered the course, and spent 6 hours every night reviewing everything for the next days class. I was actually shaking stood up to deliver a lecture on a new section. The good news was even though I felt like it hadn’t gone that well, I got glowing reviews from the students.
Soon after I dived full time back into consulting with a company. I had many assignments helping mentor development organizations and a ton of classes and custom class deliveries. In 6 months I actually taught 21 different week long courses. The work was brutal, but eventually I got the confidence in my abilities back, and I can almost effortlessly present on technical topics with just a small amount of prep time. Over the last 6 months I’ve come back to almost full time coding and even gotten to do a nice Groovy/Grails/jQuery project utilizing 1 week iterations.
I’ve read many times about how many technical managers make the mistake of letting themselves get promoted and then they can’t let go of the coding. And many technical managers point out the need to focus on the management tasks of the job. My approach to this was to focus on the management of my team, but to keep my skills fresh by doing side projects at home, presenting at user groups, and doing code reviews and maintaining build servers at the office. I don’t think this is the common approach of development managers, but it’s the only approach I’ve felt comfortable with. I do remember feeling some camaraderie with Rands (of Rands in Repose) as he proposes:
“I’m still cringing. Someone is already yelling at me, “MANAGERS OWNING FEATURES??!?!” (And I agree.) You are still a manager, so make it a small feature, ok? You’ve still got a lot to do. If you can’t imagine owning a feature, my back-up advice is to fix some bugs. You won’t get the joy of ownership, but you’ll gain an understanding of the construction of the product that you’ll never get walking the hallway.”
— Rands
So the fallback plan is just as important as the financial advice you always get to make sure you have at least 6 months of salary socked away so you can ride out a layoff. Rather than fighting for nearly nonexistent management positions in a bad economy I was able to step into development and do important work. While I love management there are aspects of development that I’m very passionate about and I may continue on this course for the next few years. I’m sure I’ll return to managing a development team as it’s in my DNA, but for now I’m enjoying firing off a ‘git commit’, seeing lots of green tests passing and building a quality app in short iterations.
Recruiting for Passion: Creative Job Descriptions

As a new manager recruiting for the first time you’ll find HR will usually provide you with a job description template. You’ll read it, laugh at how generic it is, and then try to do a bit of modification. That’s a futile effort. (Though depending on the organization you may have to leave pretty close to the strict confines of a template, in that case you’ll be working with a few custom bullet points you can work in.)
You’re actually looking for the most talented, passionate developers you can find given the opportunity, your location, and the relative pay rates provided. So how do you attract those people with a generic job posting? Instead you rewrite the position from scratch and ask for things like writing plugins to open source frameworks, giving presentations at conferences, or writing a technical blog. You want to attract developers who care about their craft and are going to bring up the overall level of your team.
So in short:
- Keep it short a paragraph or two and bullet points. The meat of the content is in the bullet points.
- Explain the challenges of your environment, if you’re a hardcore waterfall shop trying to shift to Agile be upfront.
- Explain that mentoring is part of the job.
- If you have the control you can even write the job description in a programming language.
- Be very clear that bringing your passion to work is encouraged.
- If you’ve won some of the wars with the furniture police, explain the nice hardware and multiple large monitors that are available, or even semi-private offices.
- If other members of the team have some public blogs, or open source projects point to those as well to give them a feel for the team.
- If you’re not in Silicon Valley or New York, sell the upside of your region (probably cheaper living).
- If HR will let you point to some of the targeted job posting sites like 37 Signals or Stack Overflow.